Created: 5/6/2014, Last Updated: 7/2/2015
If you are new to the globalization concept, please read this: What is Globalization?.
Summary
When using Oracle GoldenGate, it's important to know how the character-based content are encoded, processed and converted during in data replications. This blog provides an overview of this topics by explaining the key concepts, describing the processes and answering the top FAQs.
When using Oracle GoldenGate, it's important to know how the character-based content are encoded, processed and converted during in data replications. This blog provides an overview of this topics by explaining the key concepts, describing the processes and answering the top FAQs.
Key Concepts
There are four types of character sets related to Oracle GoldenGate globalization processing:
1. GGSCI
Sessions refer to the connection session Oracle GoldenGate extract and replicat processes to the source/target data store. Oracle GoldenGate extract and replicat processes set up the session character set when connecting to the databases.
The globalization process is explained as shown in the following diagram:
There are four types of character sets related to Oracle GoldenGate globalization processing:
- Operating system
- Terminal
- DB character set, DB N-charset
- DB client/session
1. GGSCI
- Always operates in the character set of the local operating system. (OS)
- File name is encoded based on the local operating system (OS).
- UTF-8 is used for table name and user tokens.
- Source database character encoding is used for CHAR/VARCHAR/CLOB.
- UTF-16 is used for NCHAR/NVARCHAR/NCLOB.
- File name is encoded based on the local operating system (OS).
- Content is encoded based on the OS encoding or the CHARSET parameter setup.
- File name is encoded based on the local operating system (OS).
- Content is encoded based on the OS encoding or the CHARSET parameter setup.
- File name is encoded based on the local operating system (OS).
- Content is encoded based on the local operating system (OS).
Sessions refer to the connection session Oracle GoldenGate extract and replicat processes to the source/target data store. Oracle GoldenGate extract and replicat processes set up the session character set when connecting to the databases.
- For Oracle databases, the session character set is set to be the same as the database character set for both extract and replicat.
- For Sybase, Teradata and MySQL, the session character set is taken from the SESSIONCHARSET option of SOURCEDB and TARGETDB, or from the SESSIONCHARSET parameter set globally in the GLOBALS file. The GLOBAL setup has lower priority.
- For other database types, it is obtained programmatically. The session character set is setup to be the same as the source database for extract and the same as the target database for replicat.
The globalization process is explained as shown in the following diagram:
The basic rules include:
- No/minimum character set conversion on the source. Except for DB2 z/OS and DB2 for iSeries, extractions on all databases doesn't involve character set conversion.
- Single character set in the trail file.
- On the replicat side, the target database character set should be an equivalent or a super-set of the source database character set. If not, use CHARMAP to map unsupported characters before apply data to the target.
- The session character set should be the same as the database character set to avoid unnecessary conversion. This is especially true for MySQL and Sybase.
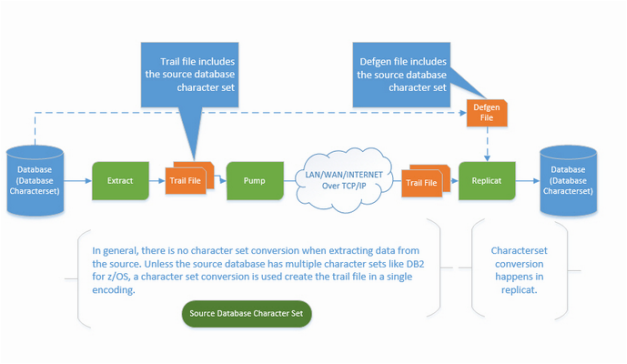
Oracle GoldenGate Character Set Conversion Process
The discussion now based on the current version of Oracle GoldenGate: 12.1.2.1.1. If you'd like to know prior version support and the differences across releases, please read this: What's New in Oracle GoldenGate Globalization Support?
Let's learn this from some examples:
Example 1: Using NOCHARSETCONVERSION to let Oracle GoldenGate use target client libraries to perform the character set conversion.
Example 2: How to use CHARMAP for invalid character set replacement?
Example 3: Replicat MySQL Database with DB Charset is UTF8 but one column in UTFMB4
DB charset : UTF8
One of Table is,
col1 : UTF8
col2 : UTF8
col3 : UTF8MB4
....
Solution: Utf8mb4 is a superset of utf8. In this case the SESSIONCHARSET can be set to be UTF-8.
Example 1: Using NOCHARSETCONVERSION to let Oracle GoldenGate use target client libraries to perform the character set conversion.
- Running replication from Tandem to DB2 z/OS.
- The trail file from the source is in ASCII.
- The target DB2 z/OS database is in EBCDIC.
Example 2: How to use CHARMAP for invalid character set replacement?
Example 3: Replicat MySQL Database with DB Charset is UTF8 but one column in UTFMB4
DB charset : UTF8
One of Table is,
col1 : UTF8
col2 : UTF8
col3 : UTF8MB4
....
Solution: Utf8mb4 is a superset of utf8. In this case the SESSIONCHARSET can be set to be UTF-8.
References
- Oracle Support Doc 1500608.1: Oracle GoldenGate - A Guide to Globalization aspects when working with OGG
- Oracle GoldenGate 12.1.2 Documentation - Supported Character Set, Supported Local
 RSS Feed
RSS Feed